カテゴリー:
-

ISO9001 2015 内部監査員育成する問題集【問題編】
★ 本記事のテーマ
ISO9001 2015 内部監査員育成する問題集【問題編】問題内容を説明します。
★ 本記事のテーマ
ISO9001 2015 内部監査員育成する問題集【問題編】★おさえておきたいポイント
- ①本問題集を作った思い・背景
- ➁本問題集は「問題テキスト」と「問題&解説ブログ」があります
- ➂問題編
- ➂問題編
- ➃演習問題を公開します
- ➄購入方法
①本問題集を作った思い・背景
内部監査員、外部審査員を
養成するための問題集の
問題内容を説明します!
–
●ISO9001 2015要求事項のおさらい
●ISO9001 2015要求事項を満たす文書群の作成
●内部監査(外部審査)の模擬演習
●監査後の受審側の改善対応
●内部・外部の課題の変化との順応
を1冊の問題集で演習できます!–
一般的な品質監査員の養成教育は
・2日コースで、2日間丸々拘束される
・一日目(終日)がISO9001 2015の復習、監査の基本的なやり方
・二日目(終日)が終日演習
・ディスカッション時間が多く、自分で考える時間が少ない
・監査報告書を書きやすくするために粗が多い問題設定が多くリアリティーに欠ける
・費用が5万円~10万円と高いなど、費用のわりに、やや不完全燃焼な講義しかないのが現状です。
そこで、
・自分の好きな時間で勉強ができて、
・ISO9001 2015の復習もできて、
・監査演習ができて、
・他にはない、監査後の改善活動まで考える演習ができる
・数千円で可能な問題集を作りました!➁本問題集は「問題テキスト」と「問題&解説ブログ」があります
問題テキスト
「➄購入方法」で説明します。
問題&解説ブログ
問題編(本サイト)と3つの解説ブログ(パスワード付き)があります。演習を進めると、解説ブログを読むことができます。
- 問題編(本ブログ)
- 解説編1(パスワードあり)
- 解説編2(パスワードあり)
- 解説編3(パスワードあり)
➂問題編
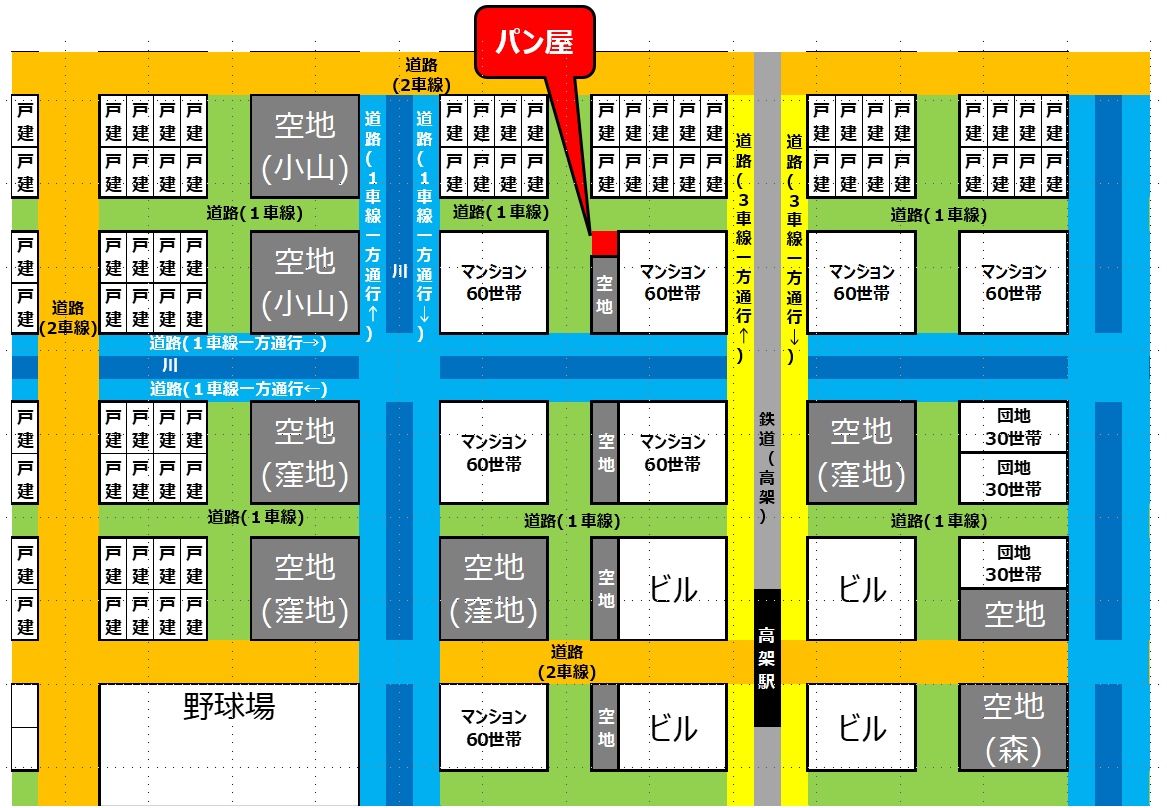
舞台は街中のパン屋さん
パン屋さんの概要
30歳の夫婦Aさん(夫)、Bさん(妻)(子供はいないが欲しいと願っている)でパン屋が今回の舞台。2人とも数年間修業して今回 街中に出店した。パン屋さん兼住宅を購入。
●営業時間:6:00-17:00
●定休日:月曜日(祝日なら火曜日)、年末年始、お盆パン屋さんの周辺は、半径200mにマンション 300世帯(1000人、車を持っている)、 戸建30世帯(100人、車を持っている)と、空地が多いが、今後建屋が増える見込みである。もう少し行って300m先に大きな高架駅がある。駅周辺に、10数階建ての大きなオフィスビル4棟が駅を囲むようにある。
なお、街1km2にパン屋さんは少ない。また、住宅は1戸20m×30mくらいと大きな家が多く、土地が広いため、自動車を使う世帯が多い。パン屋さんに数台の駐車スペースがある。自分の店の強みの1つとして、ISO9001 2015を取得しようと、ISOプロのあなたにコンサル・内部監査官を依頼している。
パン屋さんと街中のイメージ
地図と、周辺の状況がわかる動画をYou Tubeにアップしています。ご確認ください。
★ 地図

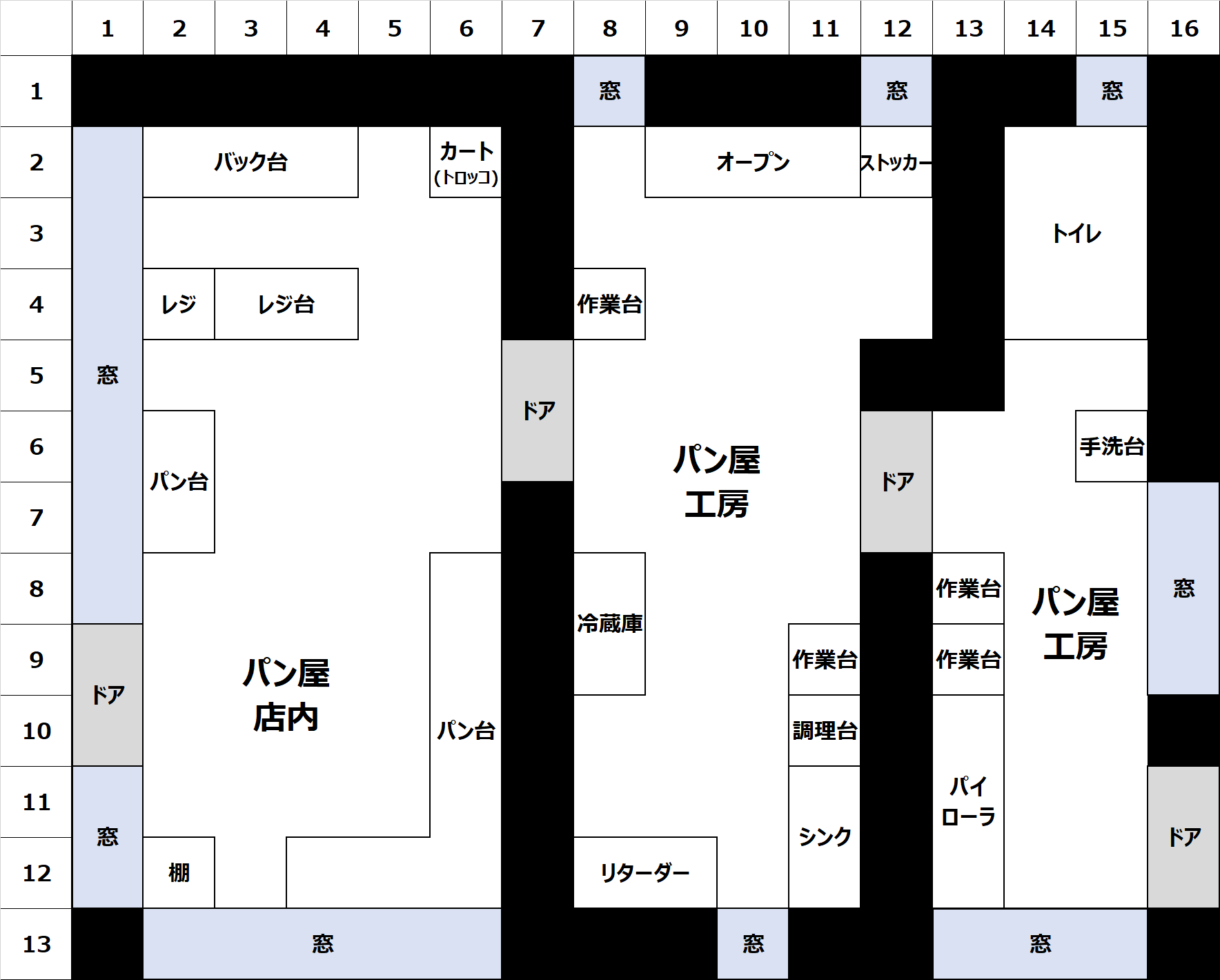
★●パン屋さん内部(ここからダウンロードできます)

★●動画(You Tube) 10分程度
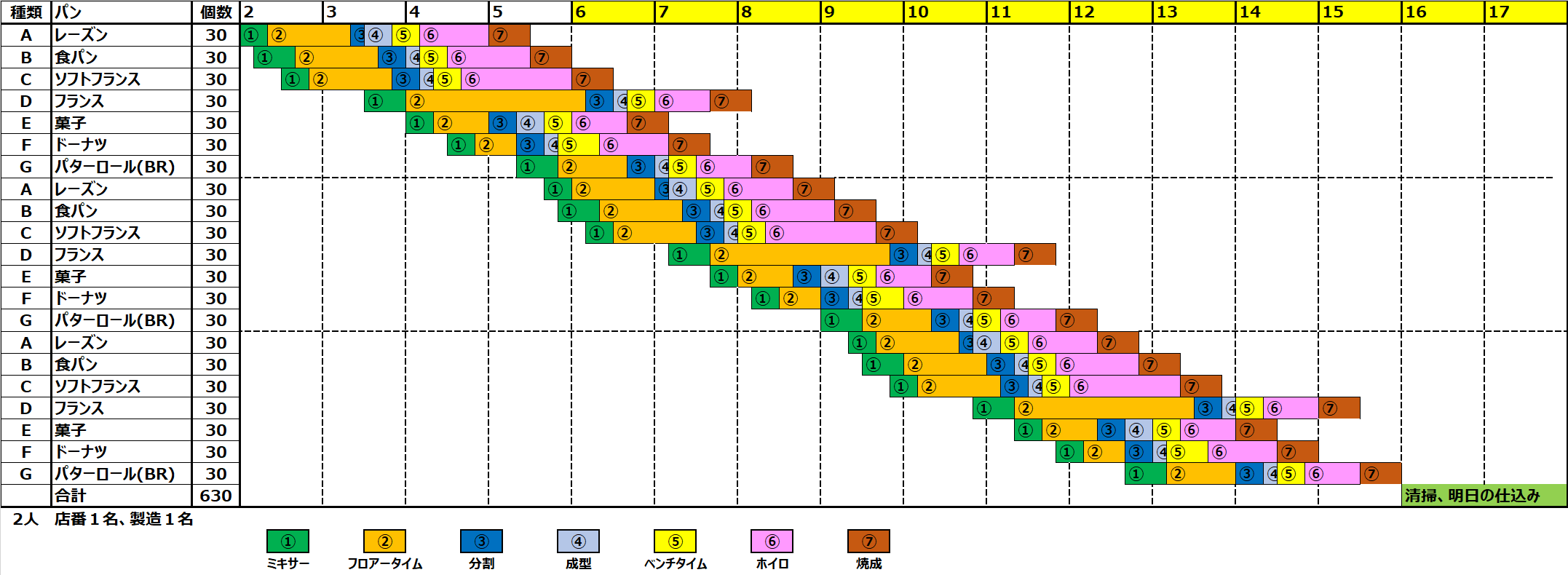
パンの製造工程
専門性を高くする必要はありませんが、販売しているパンの種類と製造方法を列挙します。
パンの製造工程は
①ミキサ
➁フロアータイム(1次発酵)
➂分割
➃成型
➄ベンチタイム
⑥ホイロ(2次発酵)
⑦焼成
と一般的な工程でパンの種類によらず、一定の時間がかかるとします。販売パンは7種類
A:レーズン
B:食パン
C:ソフトフランス
D:フランス
E:菓子パン
F:ドーナツ
G:バターロール
とします。
実際、パン屋工房内には、オーブンが1台しかないため、オーブンをフル活動できるように時間調整しながらパン製造をしていきます。
パン屋さんの情報は以上です。だいぶイメージが付いたかと思います。では、ISO9001 2015と品質監査に向けた準備をしてきましょう。
➃演習問題を公開します
21問あります。紹介します。
第1章 ISO901 2015要求事項を満たす文書群を作成
舞台の街中パン屋さんに必要なISO9001 文書群を構築します。ISO9001 の復習・応用演習になります。
–
★【1】ISO90012015の適用範囲
パン屋さんで取得する場合の、ISO9001 2015の適用範囲をどう設定するか、考えよ。★【2】外部の課題、内部の課題
ISO9001 2015の要求事項4.1において、「パン屋」の外部の課題、内部の課題を列挙せよ。また、あなたがAさんになって、パン屋さんの数年間の中計を立てよ。【3】~【15】は略(ご購入後、確認できます。
–
★【16】内部監査
ISO9001 2015の要求事項9.2において、「パン屋」の内部監査の監査実施結果報告書のフォーマットを作成せよ。第1章で構築した文書群にさらに内容を肉付けして、第3章の内部監査の準備を整えましょう。第2章 初めての内部監査
【17】~【18】は略(ご購入後、確認できます。
–
★【19】監査員役であるあなたによる内部監査評価
【17】【18】の資料をもとに、内部監査を実施したとする。その監査結果を評価し、内部監査報告書にまとめよ。第3章 初めての内部監査
本問題集にしかないオリジナル問題で、監査後のフィードバックや継続的改善も演習しましょう。監査は手段、目的は改善ですからね!
–
★【20】不適合の是正処置
【19】監査結果から不適合箇所がある。その不適合箇所の是正処置をあなたがAさんの立場で実施せよ。第4章 Aさんパン屋さんのハプニング
本問題集にしかないオリジナル問題で、ISO9001取得組織にはあまりない事象かもしれませんが、常に内外の環境変化に対応していく強さも必要です。パン屋さんに降りかかるリスクを洗い出し、品質文書群のどこをどう更新・変更すればよいかを考える章です。
–
★【21】ハプニング発生時の対応
次のハプニングが起こった場合、それぞれのリスクや機会を考えて、ISO文書群のどこをどう変更管理すればよいかを考えよ。
(1) 実は、思っていたほど売上がなく、赤字になった場合
(2)(3)略
(4) 近くに競合パン屋さん(Aさんのパン屋さんより大きなパン屋さん)が開店した場合問題は以上となります。
●ISO9001 2015要求事項のおさらい
●ISO9001 2015要求事項を満たす文書群の作成
●内部監査(外部審査)の模擬演習
●監査後の受審側の改善対応
●内部・外部の課題の変化との順応
を1冊の問題集で演習できます!解説も充実!
丁寧な解説ページやQCプラネッツのブログ記事を活用してわかりやすく解けますので、ご安心ください。
是非、ご購入ください。
➄購入方法
本ブログとメルカリとnoteから販売しております。
「QCプラネッツ」で検索ください。本ブログからのご購入
ご購入いただけます。ご購入後、QCプラネッツからアクセスサイト先(アクセスのみ可)をご案内いたします。データの拡散を防ぐため、ダウンロードと印刷は不可とさせていただきます。
メルカリでの販売
「QCプラネッツ」で検索ください。

3000円/1冊
とさせていただきます。ご購入よろしくお願いいたします。noteでの販売
電子販売もしています。こちらへアクセスください。

noteからでもご購入できます! まとめ
「ISO9001 2015 内部監査員育成する問題集」を販売します」、ご購入よろしくお願いいたします。
- ①本問題集を作った思い・背景
- ➁本問題集は「問題テキスト」と「問題&解説ブログ」があります
- ➂問題編
- ➂問題編
- ➃演習問題を公開します
- ➄購入方法



品質不正問題をしっかり解けるための重要問題集を販売します

「品質不正を勉強してもわからない、頭に入らない!」、など、困っていませんか?
こういう疑問に答えます。
本記事のテーマ
- ①品質不正はなぜ起こるか正しく分析できていますか?
- ➁問題集のメリット
- ➂内容の範囲
- ➃【問題集ご購入方法】
記事の信頼性
記事を書いている私は、QCをすべて研究して究めました。
さらに、ブログで30社以上品質不正を深く分析し、その経験をまとめた
実務で十分活用できる品質不正を深く分析できる問題集を作りました!
①品質不正はなぜ起こるか正しく分析できていますか?
他人事じゃないでも品質不正がいまいちわからない
●品質不正をないがしろにするとどうなるか?わからない
●不正しない個人が集まる組織がなぜ不正するのか?
●報告書、メディア情報がたくさんあるが、結局何が原因なのかが完全にはわからないからスッキリしない!
●報告書が提示する再発防止策はたくさんあるが、本当に再発防止できるのか?
●その組織が品質不正した真因を自分で深く正しい分析したい
●品質不正事例をたくさんあつめたい!
●品質不正から経営課題やその組織の本当の問題が知りたい!
●再発防止がなぜできない企業があるのか知りたい!
●今後も新たな不正問題が出て来るが、すぐに真因を特定できるようになりたい!
と願望あるけど、正しく的確に分析して、未然防止につなげたいけど、なかなか難しいから困りますよね
品質不正を深く正しく分析できて、
自組織の未然防止に役立つ問題集がないのか!
という思いから今回、
問題集を作成しました!
➁問題集のメリット
本問題集を学ぶメリット
- 不正しない個人が集まる集団が不正する理由を深く考えることができる
- 不正に走る圧力・黒幕が何か?が30社以上の分析からわかる
- QCDバランスモデルを使って品質不正問題を的確に解ける
- 再発防止策は万全か?なぜ再発するのか?も理解できる
- 品質不正した企業事例を使って演習できる
- 本演習問題を解けば、今後新たな組織・企業が品質不正を報告してもすぐに真因や背景がわかる
- だから、自組織に展開すれば未然防止に役立つ
- 品質不正にかかる費用は数億円。本問題集を買えばその巨額損失が減らせる!
本問題集1,500円お買い上げいただき、勉強して自組織に展開して数億円の損失が防げたら、コスパ数万倍ですからね。マジで!
逆にデメリットは
- 勉強しないと習得できない
⇒それはしゃーない!ですよね(笑)
是非、ご購入いただきたいです。
次に、全問題の内容を紹介します!
➂内容の範囲
問題集の全問題を紹介!
33題の問題内容と単元を紹介します!
品質不正を考えやすくするために流れを意識して作っております!
30社以上の豊富な品質不正事例を演習
| 章 | 第 | 問題 |
| 1 | 1 | 品質不正問題を真剣に取り組まなければどうなるか? その1 |
| 1 | 2 | 品質不正問題を真剣に取り組まなければどうなるか? その2 |
| 1 | 3 | 品質不正問題を真剣に取り組まなければどうなるか? その3 |
| 2 | 4 | 品質不正の情報収集方法とその注意点 |
| 2 | 5 | 不正のトライアングルモデルは十分か? |
| 2 | 6 | 品質不正報告書の原因と再発防止策で十分か? |
| 2 | 7 | 数百、千ページにもわたる品質不正報告書を速く読み取る方法 |
| 3 | 8 | 不正する社員は必ず数%はいる。 |
| 3 | 9 | 悪意ない個人集団が品質不正に陥るのはなぜか? |
| 3 | 10 | 不正せざるを得ない真因とは何か? |
| 4 | 11 | QCDモデル |
| 4 | 12 | 品質不正が起こるパターン |
| 4 | 13 | 品質不正が起こるパターン① |
| 4 | 14 | 品質不正が起こるパターン➁ |
| 4 | 15 | 品質不正が起こるパターン➂ |
| 4 | 16 | 品質不正が起こるパターン➃ |
| 4 | 17 | 品質不正が起こるパターン➄ |
| 4 | 18 | あなたが所属する組織では、不正温床はないか? |
| 5 | 19 | ケース1 小林化工から品質不正を学ぶ |
| 5 | 20 | ケース2 日医工の品質不正を学ぶ |
| 5 | 21 | ケース3 ジャムコの品質不正を学ぶ |
| 5 | 22 | ケース4 スバルの品質不正を学ぶ |
| 5 | 23 | ケース5 日産自動車の品質不正を学ぶ |
| 5 | 24 | ケース6 神戸製鋼の品質不正を学ぶ |
| 5 | 25 | ケース7 三菱電機の品質不正を学ぶ |
| 5 | 26 | ケース8 フォルクスワーゲンの品質不正を学ぶ |
| 5 | 27 | ケース9 ビッグモータの品質不正を学ぶ |
| 5 | 28 | ケース10 三菱自動車の品質不正を学ぶ |
| 5 | 29 | ケース11 2023年度に発生した品質不正ケースを学ぶ |
| 6 | 30 | 三菱電機の品質不正から |
| 6 | 31 | 三菱自動車の品質不正は再発防止できるか? |
| 7 | 32 | 品質監査で不正は見抜けるか? |
| 7 | 33 | 品質不正に巻き込まれないために |
33問をしっかり解いていきましょう。
問題を公開します!
不安な問いがないかどうか、チェックしましょう。1つでも解けない、不安な問いがあればご購入いただき、一緒に勉強しましょう!
第1章 なぜ品質不正問題が大事なのか?
【1】品質不正問題を真剣に取り組まなければどうなるか? その1
【2】品質不正問題を真剣に取り組まなければどうなるか? その2
【3】品質不正問題を真剣に取り組まなければどうなるか? その3
第2章 品質不正の情報収集と分析方法
【4】品質不正の情報収集方法とその注意点
【5】不正のトライアングルモデルは十分か?
不正のトライアングルにふさわしい3つの用語をあなたも考えて提案せよ。
【6】品質不正報告書の原因と再発防止策で十分か?
(1) 再発防止策としてどんなものがあるかいくつか例示せよ。
(2) (1)の対策群で本当に再発防止になるか、考えよ。
【7】数百、千ページにもわたる品質不正報告書を速く読み取る方法
第3章 組織員に悪意はあるか?
【8】不正する社員は必ず数%はいる。
【9】悪意ない個人集団が品質不正に陥るのはなぜか?
【10】不正せざるを得ない真因とは何か?
第4章 QCDバランスモデルを使って品質不正を深く分析
【11】QCDモデル
【12】品質不正が起こるパターン
そのグルーピングできるモデルをいくつか挙げよ。
【13】品質不正が起こるパターン①
【14】品質不正が起こるパターン➁
【15】品質不正が起こるパターン➂
【16】品質不正が起こるパターン➃
【17】品質不正が起こるパターン➄
【18】あなたが所属する組織では、不正温床はないか?
第5章 品質不正の事例から分析
【19】ケース1 小林化工から品質不正を学ぶ
【20】ケース2 日医工の品質不正を学ぶ
【21】ケース3 ジャムコの品質不正を学ぶ
【22】ケース4 スバルの品質不正を学ぶ
【23】ケース5 日産自動車の品質不正を学ぶ
【24】ケース6 神戸製鋼の品質不正を学ぶ
【25】ケース7 三菱電機の品質不正を学ぶ
【26】ケース8 フォルクスワーゲンの品質不正を学ぶ
【27】ケース9 ビッグモータの品質不正を学ぶ
【28】ケース10 三菱自動車の品質不正を学ぶ
【29】ケース11 2023年度に発生した品質不正ケースを学ぶ
●2023/10/24 沢井製薬の品質試験不正
●2023/9/7 菓子メーカー(シャトレーゼ子会社、菜花堂社)で起きた賞味期限の書き換え
●2023/5/29 化学メーカー(東洋スチレン社)で起きた品質不正
●2023/5/22 メーカー(トヨタグループ、愛知製鋼社)で起きた品質不正
●2023/5/19 メーカー(日立Astemo社)で起きた品質不正で調査報告書を公表
●2023/5/3 インフラ業界(熊谷組社など4社が行う、北海道新幹線のトンネル工事)で起きた検査不正
●2023/4/28 製造業(ダイハツ工業社)で起きた検査不正
●2023/3/29 製造業(日本軽金属HD社)で起きた検査不正
●2023/3/25 製造業(川崎重工子会社の川重冷熱工業社)で起きた検査不正
●2023/3/16 インフラ業界(大成建設社)で起きた施工不良
●2023/2/24 製造業(ニプロファーマ社)で起きた検査不正
【30】三菱電機の品質不正から
【31】三菱自動車の品質不正は再発防止できるか?
第7章 自組織が品質不正に巻き込まれないための施策
【32】品質監査で不正は見抜けるか?
【33】品質不正に巻き込まれないために
解説も充実!
丁寧な解説ページやQCプラネッツのブログ記事を活用してわかりやすく解けますので、ご安心ください。
是非、ご購入ください。
➃【問題集ご購入方法】
「QCプラネッツ」で検索ください。
本ブログでの販売

1500円/1冊
とさせていただきます。ご購入よろしくお願いいたします。
[asp_product id=”21425″]
noteでの販売
電子販売もしています。こちらへアクセスください。
 |
品質不正問題をしっかり解けるための重要問題集を販売します |
まとめ
「品質不正問題をしっかり解けるための重要問題集」を販売します」、ご購入よろしくお願いいたします。
- ①品質不正はなぜ起こるか正しく分析できていますか?
- ➁問題集のメリット
- ➂内容の範囲
- ➃【問題集ご購入方法】

ISO9001 2015を自分のものにする応用問題集を販売します
★ 本記事のテーマ
- ①ISO9001 2015を事業に活かせていますか?
- ➁問題集のメリット
- ➂内容の範囲
- ➃【問題集ご購入方法】
★ 記事の信頼性
記事を書いている私はQCをすべて研究して究めました。
さらに、実務で組織のISO9001 担当で内部監査・外部審査経験も豊富です。
究めた結果、実務で十分活用できるISO9001 2015を習得できる問題集を作りました!
①ISO9001 2015を事業に活かせていますか?
なんちゃってISOな人になっていませんか?
品質管理で飯食っている人のほとんどが、
こんな人を「なんちゃってISOな人」です
- 品質管理業務しているけど、ただの管理部門の不思議ちゃんにすぎない
- ISO9001 2015要求事項を理解しているだけで、何も組織は改善されていない
- ISO9001 2015要求事項をどう活用すれば、組織が有効的に改善するか?ポイントがわかっていない。品質用語を暗記だけしている
- ISO9001 2015を使って体系的に擬似体験できるような実践演習の経験がないから、周囲の見様見真似で誤魔化している!
- ISO9001 2015をつかってどうやって組織改善や改革を進めてよいかの勘所がわからない!
- ISO9001 2015を理解させる優れた演習や教材が無くて困っている!
すいません。私の職場そのものです。
ホンモノのISOな人になりませんか?
組織は品質管理専門がいないから、なんちゃってでも誤魔化せるんですが、それでいいのか?誤魔化す人生でいいのか?とプロ意識があるはずです。
ISOを活用し、組織で指導できれば立派に食べていけるんです! ただその教科書や演習問題が無い!
ISO9001 2015 要求事項をどうやって組織に活かしていくかのポイントがわかる稀有な問題集です。
ISOコンサルでもここまでの手の込んだ問題集は作っていません。
そこで、今回
舞台となる組織を仮定し、
その組織の
●経営方針、品質方針、
●それに整合する品質目標、組織体制、力量、資源、コミュニケーション
をすべて設計し、
●その組織が求めるISO9001の適用範囲を設定し、
●マネージメントレビューまでの一連の流れを
すべて準備して演習問題集を作りました!
手間かけて問題集を作りました!
だって、ISO9001 2015のスキルも磨けるし
品質管理技術者としての勘所も磨ける!
QCプラネッツはこういうのを作らないといけないですよね!
そこでの品質活動を設計し、どうやってISO9001 2015を満たすレベルにあげていくかを考える問題を通じて、ISO9001 2015を実践で活かせるスキルを磨くことができます。
➁問題集のメリット
本問題集を学ぶメリット
- 2015を自分のモノにする!
- ISO9001 2015をベースに自分の組織を改善できるリーダーシップが磨ける
- 未熟な組織を使って演習するから、どこを改善すべきかが実践で習得できる!
逆にデメリットは
- 勉強しないと習得できない
⇒それはしゃーない!ですよね(笑)
是非、ご購入いただきたいです。
次に、全問題の内容を紹介します!
➂内容の範囲
問題集の全問題を紹介!
20題の問題内容と単元を紹介します!
1つでも説明に困る場合は、是非ご購入いただき、ISO9001 2015を自分のものにしましょう。
★第1章 I SO9001 ここがわからない
★【1】なぜケースメソッドでISO9001 2015を勉強するのか?
★【2】ケーススタディ
「●○塾」
Aさんは人口10万人程度の地方中心都市で理数系強い進学塾を経営している。
教室は1か所(2教室、1教室定員20名)で事務1名、講師はAさんを含む3名
10年以上、同じ教室で塾を経営していきた。
中高数学、中高理科(高校物理):Aさん
高校化学、中学社会、中学国語、事務 :1名(Bさん=Aさんの妻)
中高英語 1名(大学生バイトCさん= Aさんの長男)
地域の高校生、中学生100名が塾生として、
地方から有名な国公立大、私立大を輩出してきた。
さらに、教育の充実、知名度アップのためにISO9001 2015を導入したいと考えているが、何をしたらよいか? 授業の準備等で忙しく、ISOを十分検討する時間がなく、ISOのプロであるあなたを呼んだ。
★第2章 ISO9001 2015を取得するためにどんな文書が必要か
★【3】ISO90012015の適用範囲
★【4】外部の課題、内部の課題
★【5】利害関係者(ステークホルダー)
★【6】品質方針
★【7】組織の役割、責任及び権限
★【8】品質目標
★【9】コミュニケーション
★【10】文書化した情報
★【11】運用・プロセス
★【12】外部から提供されるプロセス,製品及びサービスの管理
★【13】苦情・不適合
★【14】顧客満足度
★【15】内部監査
★第3章 ISO9001 2015 初めての内部監査
★【16】内部監査実施
★第4章 ISO9001 2015 内部監査後の継続的改善
★【17】内部監査後の継続的改善
★第5章 ISO9001 2015 マネージメントレビュー
★【18】マネージメントレビューのインプット
★【19】マネージメントレビューのインプット
★【20】マネージメントレビューのアウトプット
20問の一連の流れを解くと、
ISO9001 2015の要求事項を使いこなせるようになり、
自組織の改善施策への道筋も明解になります!
解説も充実!
丁寧な解説ページやQCプラネッツのブログ記事を活用してわかりやすく解けますので、ご安心ください。
是非、ご購入ください。
➃【問題集ご購入方法】
「QCプラネッツ」で検索ください。
本ブログからのご購入
ご購入いただけます。ご購入後、QCプラネッツからアクセスサイト先(アクセスのみ可)をご案内いたします。データの拡散を防ぐため、ダウンロードと印刷は不可とさせていただきます。
メルカリでの販売
「QCプラネッツ」で検索ください。

2000円/1冊
とさせていただきます。ご購入よろしくお願いいたします。
noteでの販売
電子販売もしています。こちらへアクセスください。
 |
ISO9001 2015を自分のものにできる応用問題集を販売します |
まとめ
「ISO9001 2015を自分のものにできる応用問題集」を販売します」、ご購入よろしくお願いいたします。
- ①ISO9001 2015を事業に活かせていますか?
- ➁問題集のメリット
- ➂内容の範囲
- ➃【問題集ご購入方法】


















































{kind=link}
{kind=link}
{kind=link}